Tutorial: CRF Learning for OCR (PGM p3.week2) - part2
Written on July 23rd , 2020 by Sergei Semenov
Previous part is here
Assignment - what is under the hood?
The programming assignment is supplied with some already implemented functions and modules. As for any other assignment in this course, it is mandatory to understand how course creators see the path we shall pass (actually, it defines 80% of success).
Selected algorithm
Here the stochastic gradient is in use. It means, that we run ascent gradient for every training sample independently. We won’t see any batches in this assignments.
How model looks exactly?
We have our initial 8 factors:
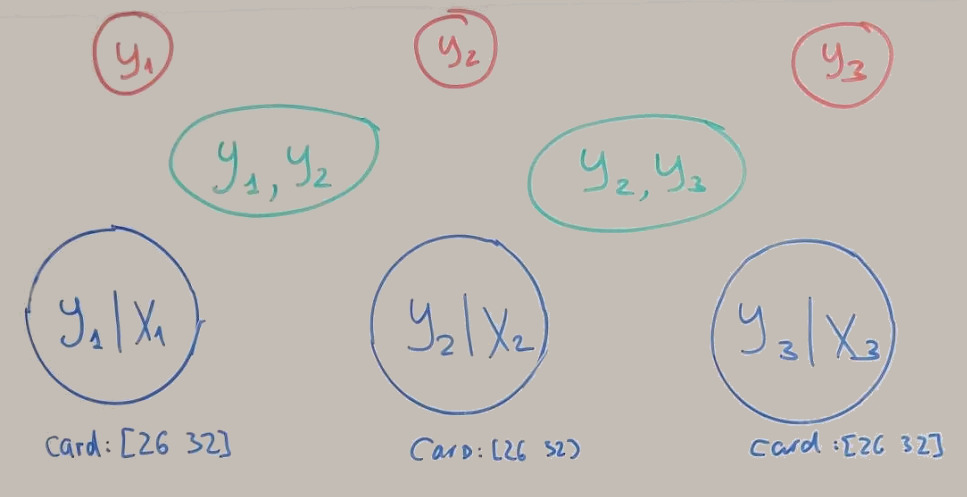
After connecting edges and calling PruneTree() (it combines factors with common parts to the one factor) we get something like:
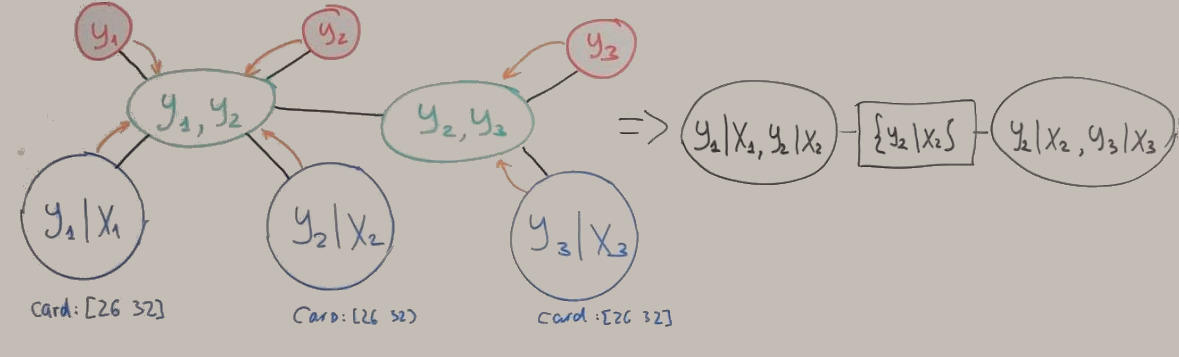
Now our model (painted with black) is relative simple. The BP for this tree requires only passing of two messages. The resulting beliefs can be used to compute marginals and conditional probabilities for every feature: \(P(Y_1 \mid X_1); P(Y_2 \mid X_2); P(Y_3 \mid X_3)\)
After that we can be calculate model expected feature count using following expression: \(E_{\theta}\left[f_{i}\right]=\sum_{\mathbf{Y}^{\prime}} P\left(\mathbf{Y}^{\prime} \mid \mathbf{x}\right) f_{i}\left(\mathbf{Y}^{\prime}, \mathbf{x}\right)\)
How features are stored in featureSet?
They are stored in the following order:
- Conditional \(F(Y \mid X)\) - first half for black pixels, second half for whites.
- Unconditional stand-alone \(F(Y)\) - actually letter frequencies.
- Unconditional pairwise \(F(Y_{i}, Y_{i+1})\).
How to implement that?
I used the following code sequence
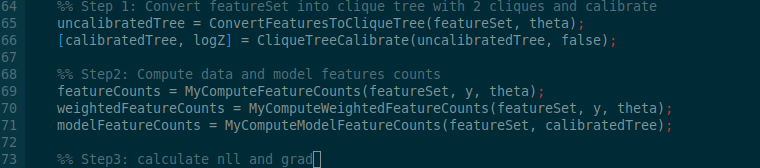
Last update:27 July 2020